計畫簡介
專案動機
身心障礙者及少數語言使用者在數位資訊與服務獲取上存在困難,例如尋求幫助或接收公共資訊時受限於語言障礙與不友善的使用者介面。
計畫目標
為促進教育、醫療及公共參與的公平性,亟需開發包容性溝通技術,以滿足不同溝通需求。本計畫開發多模態跨語言任務導向對話系統,整合語音、文字、影像等多種輸入方式,支援中文、英文、閩南語、客家語、越南語等多語言,為語言障礙者提供無障礙的溝通輔具。
合作夥伴
合作夥伴選擇
目前與五個非營利組織合作,包括中華民國腦性麻痺協會、漸凍人協會、陽光社會福利基金會、勵友中心、行無礙協會,這些組織直接服務於有溝通障礙的個體。未來會再增加一個高雄無礙玩家。
數據來源與處理
從合作組織的網站、內部文件及訪談中收集領域特定內容,進行文本清理與分割,形成結構化語料庫,並通過FAISS進行向量化索引。
合作組織
中華民國腦性麻痺協會
漸凍人協會
陽光社會福利基金會
勵友中心
行無礙資源推廣協會
AIITNTPU
智慧客服系統
我們已成功建置6套專屬的LINE Bot智慧客服系統,每套系統都針對特定組織的需求進行客製化,提供24小時不間斷的溝通支援服務。
系統特色
- 多模態輸入:支援文字、語音、圖片
- 專屬資料庫:每個組織擁有客製化知識庫
- RAG技術:檢索增強生成,提升回答準確性
- 跨語言支援:中英文、閩南語、客家語
- 即時回應:24/7不間斷服務
使用情況
LINE Bot 實際對話展示

6套專屬LINE Bot智慧客服系統實際對話介面展示
服務組織:
技術架構
本系統採用RAG(檢索增強生成)架構,結合多模態嵌入模型、向量資料庫和大型語言模型,實現精準的跨語言對話服務。
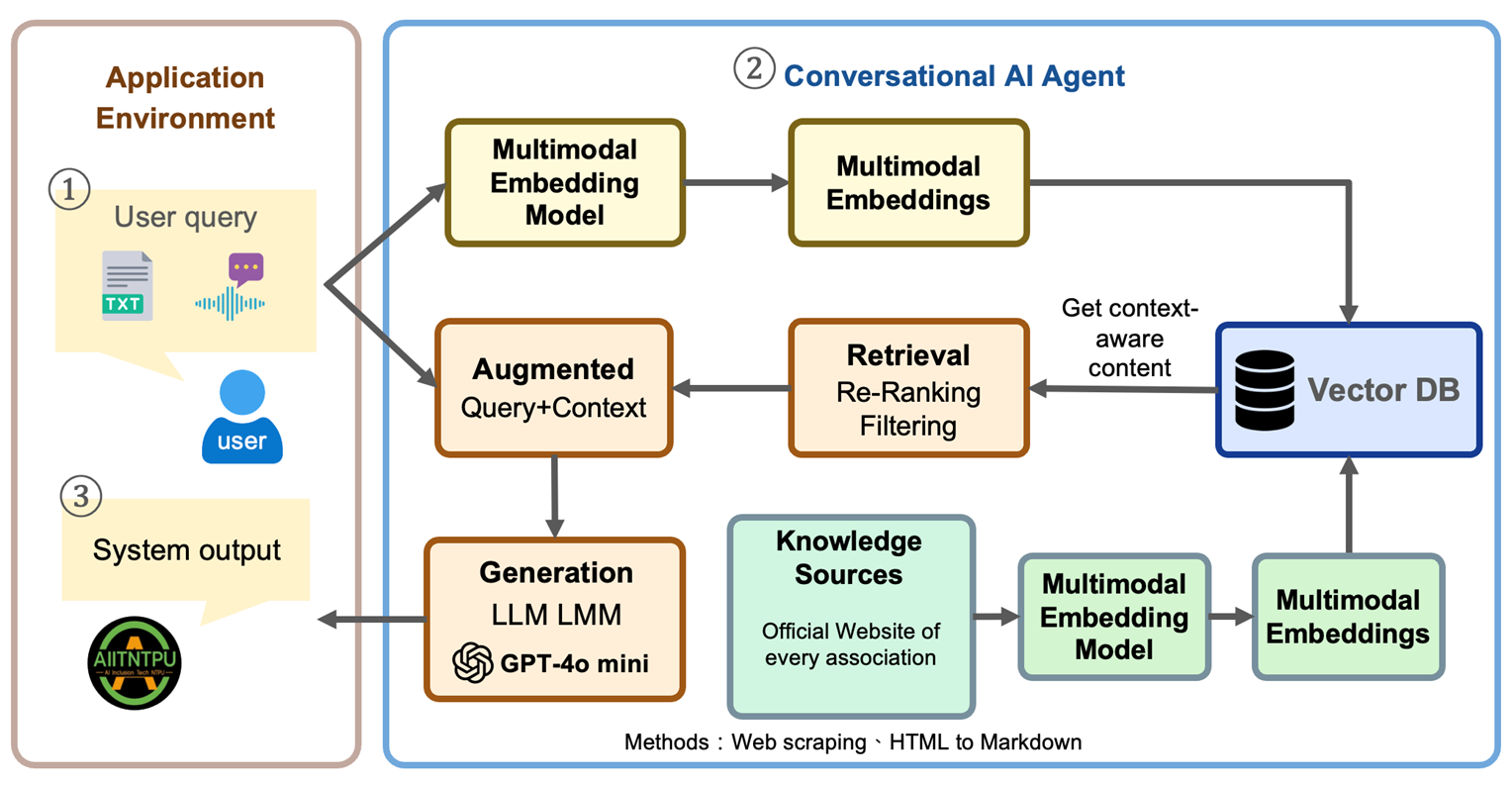
RAG增強的多模態跨語言對話系統架構
輸入處理
- • 多模態嵌入模型
- • 語音轉文字(ASR)
- • 圖像識別處理
檢索處理
- • 向量資料庫檢索
- • 上下文感知過濾
- • 相關性重新排序
生成輸出
- • GPT-4o mini 生成
- • 多語言回應
- • 文字轉語音(TTS)
發展歷程
第一階段:本地Python與Flask實現
使用SentenceTransformer嵌入與FAISS檢索,OpenAI的GPT-4o-mini API生成響應。
第二階段:遷移至Google Cloud Run
加入語音功能,使用Whisper模型。
第三階段:採用多語言模型
採用multilingual-e5-base模型嵌入,OpenAI的GPT-4.1 API生成,NVIDIA NIM API與Gemma-3 27B模型處理圖像。
未來規劃
多語支援擴展
新增越南語,強化跨語言應用能力。
多模態互動設計
Web端支援多模態輸入與問答;LINE端維持輕量文字對話,確保穩定性。
技術與模型更新
導入Gemma 3、Whisper與LLaVA-NeXT等模型,建構RAG核心架構,提升多語與多模態效能。
持續優化系統
蒐集使用回饋,優化回應品質與操作介面。
實地推廣部署
拓展至6+1個場域,驗證系統穩定性與實用性。目標服務人次超過100人次,持續改善使用者體驗。
共同打造包容性溝通環境
讓科技成為連結每個人的橋樑
聯絡我們